midSemExam gpu
]### Chapter 2
Kernel in Context of GPU¶
- A kernel is a function designed to run on the GPU and perform specific tasks
Serial/Parallel Problems¶
- Threads operate with a shared memory space
- Adv -> not having to exchange data via messages
- Dis -> Lack of protection of shared data.
- Threading model sits well with OpenMP
- Process model sits well with MPI (Message Passing Interface)
Concurrency & Locality¶
Concurrency¶
- Concurrency refers to the ability of the GPU to perform multiple tasks in overlapping time periods.
- Concurrent execution of multiple kernels
- Embarrassingly parallel problems
- If you can construct a formula where the output data points can be represented without relation to each other.
- CUDA is ideal for this type of problems
- For most kernels, the number of blocks needs to be in the order of eight or more times the number of physical SMs on the GPU.
- A typical GPU has on the order of 24K active threads.
Locality¶
- High amounts of power and time are consumed in moving the operands to and from these functional units.
- Temporal Locality
- Spatial Locality
- CPUs are designed to run software where the programmer does not have to care about locality.
- Eviction and dirty data management is one downside of caching approach
- Dirty data has to be written back to global memory before the cache space can be used again
Parallelism Types¶
Pipeline Parallelism (Task Based Parallelism)¶
- output of one program provides input to the other
- uses | operator
- Bottleneck -> Runs only as fast as the slowest component.
- Amdahl's law
- Maximum Speedup is one divided by the fraction of the program that takes the longest time to execute $\(\frac{1}{longest\ execution\ time\ of\ FRACTION\ of\ program}\)$
- Ultimately, you will have serial operations, and will be using CPU.
- Even if you move everything to GPU, you will still use CPU to load and store data to and from storage devices.
- Maximum theoretical speedup is the fraction of the program that performs the computation/algorithmic part, plus the remaining serial function. $\(Maximum\ Speedup\ = \ Algorithmic\ Part \ + Serial\ Function\)$
Coarse-grained parallelism¶
- Coarse-grained parallelism is a type of parallel computing where a program is split into large tasks, allowing for a significant amount of computation to occur in processors
- Task based parallelism fits better with this
Data-based Parallelism¶
- Focus is on how data needs to be transformed rather than how tasks need to be performed.
- Data is split into parallel and each section is processed in parallel.
- GPUs does not maintain cache-coherency. Thus GPU is able to scale to a far larger number of cores (SMs --> Streaming Multiprocessor) per device as compared to CPUs.
- Fermi and Kepler GPUs -> a shared L2 cache that replicates the L3 cache function on the CPU.
- GPUs handle parallelism more efficiently by launching multiple kernels and ensuring sufficient block distribution.
Flynn's Taxonomy¶
- SISD, SIMD, MISD, MIMD
- Serial Programming --> SISD
- Dual,Quad Core desktop Machines today --> MIMD
- SIMT (Single Instruction Multiple Threads) is used by NVIDiA.
- It is a flexible form of SIMD
Some Common Parallel Patterns¶
Loop-based patterns¶
- Iteration dependency is where one iteration of the loop depends on one or more previous iterations.
- Loop-based iteration is one of the easiest patterns to parallelize.
- For CPU, this is simply the number of logical hardware threads available.
- GPU is the number of SMs multiplied by the maximum load we can give to each SM, 1 to 16 blocks.
- An existing multi-core CPU solution, typically has far too large a granularity for a GPU.
- CPU is coarse-grained, it is good for fewer more complex tasks
- GPU is more granular, good for many smaller, parallel tasks.
- Most loops can be flattened, thus reducing an inner and outer loop to a single loop.
- Small loops present considerable loop overhead, typically not efficient.
Fork/Join Pattern¶
- There can actually be millions of data items and attempting to fork a million threads will cause almost all OSs to fail in one way or another.
- To avoid this, OS applies a "fair" scheduling policy
- On CPUs, libraries will use the number of logical processor threads available as the number of processes to fork.
- On GPUs, it's more like a block pool than a thread pool.
- Block pool here indicates (Currently Available blocks that can be executed). Each block on GPU can have N threads varying by GPU Generation.
Tiling/Grids¶
- Used by CUDA to break the problems into smaller parts
- To achieve good performance on any platform, two key concepts must be considered --> Concurrency and Locality
- Tiling model is easy to Conceptualize. If you have a linear distribution of work within a single block, you have an ideal decomposition into CUDA blocks.
- For most GPUs, you'll find an ILP (Instruction Level Parallelism) level of four operation per thread works best.
Divide and Conquer¶
- Quick Sort
- Most recursive algorithms can also be represented as an iterative model, which is usually somewhat easier to map onto the GPU.
- Available stack can be queried with API call
cudaDeviceGetLimit()and set withcudaDeviceSetLimit() - Debugging tools --> Parallel Nsight, CUDA-GDB
- a recursive algorithm be aware that you are making a tradeoff of development time versus performance.
- Use iterative solutions where possible as they will generally perform much better and run on a wider range of GPU hardware.
Chapter 3 -- CUDA Hardware Overview¶
PC Architecture¶
- All GPU devices are connected to the processors via the PCI-E (Peripheral Component Interconnect - Express) bus
- Northbridge
- For data from the processor to GP{U -> FSB (Front Side Bus)
- Memory is accessed through Northbridge
- Peripherals are accessed through the Northbridge and Southbridge chipset
- Northbridge deals with all high-speed components --> memory, CPU, PCI-E, etc.
- Southbridge
- deals with slower devices --> Hard disk, USB, keyboard, network connections, etc.
- PCI-E
- Based on guaranteed bandwidth
- Since PCI-E 2.0, we get same upload and download speed, at same time.
- We can transfer 5GB/s to the card while receiving 5GB/s from the card.
- This bandwidth is not cumulative though, you cannot send/receive 10GB/s
- Nehalem Architecture
- Introduced QPI(Quick Path Interconnect), an improvement over FSB(Front Side Bus)
- QPI --> High speed inter connect to talk to other devices or CPUs.
- QPI runs at either 4.8 GT/s or 6.4 GT/s. (GT -> Giga Transfers per second)
- Introduced QPI(Quick Path Interconnect), an improvement over FSB(Front Side Bus)
- Sandybridge Design
- From I7/X58, intel started using this
- Support for SATA-3 standard -> Supporting 600 MB/s transfer rates
- Introduced AVX(Advanced Vector Extensions) instruction set.
- Allows for vector instructions that provide up to four double precision(256bit/32byte) wide vector operations.
- Downside --> Supports only 16 PCI-E lanes, limiting PCI-E bandwidth to 16 GB/s in theory and 10 GB/s in actual bandwidth.
- Intel
- Uses triple or quad channel memory on top-end systems
- dual channel memory on lower-end systems
- AMD
- Dual channel memory only
- Supports up to six SATA 6GB/s ports.
GPU Hardware¶
- GPU Hardware consists of a number of key blocks
- Memory (Global, Constant, Shared)
- Streaming Multiprocessors (SMs)
- Streaming Processors (SPs)
- GPU is really an array of SMs, each of which has N cores
- G80/G200 -> 8 cores
- Fermi -> 32-48 cores
- Kepler -> 8+ Cores
- There are multiple SPs in each SM.
- Each SM has access to something called a register file, a chunk of memory that runs at same speed as SP units, giving an effectively zero wait time on this memory.
- Used for storing registers within threads running on an SP
- There is also a shared memory block accessible only to the individual SM -- Used as program-managed cache
- Each SM has a separate bus into the texture memory, constant memory and global memory space
- Texture Memory -> Special view onto the global memory
- Useful when there is data interpolation (2D or 3D lookup tables)\
- Constant Memory
- used for read-only data and is cached on all hardware revisions
- Global Memory
- supplied via GDDR (Graphic Double Data Rate) on graphics card
- High performance version of DDR memory
- Texture Memory -> Special view onto the global memory
- Each SM also has two or more special purpose units (SPUs)
- for performing special hardware instructions --> high speed 24 bit sin/cosine/exponent operations.
CPUs and GPUs¶
- Programming is a very low level affair
- Sloppy code means poor use of the CPU and available memory, which could translate into needing a faster CPU or more memory.
- To really get performance out of the hardware, you need to understand how it works.
Compute Levels¶
Compute 1.0¶
- Found on older graphic cards.
- lacked feature for atomic operations -> Couldn't guarantee a complete operation without any other thread interrupting.
- Hardware implements a barrier point at entry of atomic functions to guarantee completion of operation (add, sub, min, max, etc.)
- Now obsolete.
Compute 1.1¶
cudaGetDeviceProperties()returns thedeviceOverlapproperty, which defines if this functionality is available. Which functionality you ask? read on..- This version brought in support for overlapped data transfer and kernel execution.
- To use this method we require double the memory space we'd normally use.
- Cycles
- GPU is idle, CPU fills Buffer 0
- GPU processes buffer 0, CPU fills buffer 1
- GPU processes buffer 1 , CPU reads from Buffer 0, Fills buffer 0.
- Continues alternatively
- Dual buffering method largely hides the latency of GPU-to-CPU and CPU-to-GPU transfers and keeps both the CPU and GPU busy.
Compute 1.2¶
- 2x number of CUDA core processors on a single card
- NVIDIA increased number of concurrent warps a multiprocessor could execute from 24 to 32.
Compute 1.3¶
- Introduction to support or limited, double-precision calculations
- A mixture of single and double precision operations can be used starting with this version.
Compute 2.0¶
- Switched to the Fermi Hardware
- Introduced
- 16k to 48k of L1 cache memory on each SP
- a shared L2 cache for all SMs
- Extension in size of shared memory from 16K per SM to 48K per SM
- Shared Memory banks increased from 16 to 32.
-
Tesla-based devices
- Support for ECC (Error Correcting Code) -- based memory checking and error correction
- support for dual-copy engines
-
Cache Introduction makes it easier for programmers to write programs that work well on GPU
- L2 cache is up to 768K in size
- ECC Memory is a must for Data centers, as it provides automatic error detection and correction. Why is it needed for data centers and not personal devices?
- Electrical devices emit small amounts of radiation, when in close proximity to other devices, this radiation can change the contents of memory cells in other devices.
- The probability of this happening is tiny, but in a data center, the equipment are densely packed, resulting in probability of something going wrong increasing to high, unacceptable levels.
- This is why ECC is needed, which in turn reduces the amount of available RAM, and negatively impacts memory bandwidth.
- Thus ECC is only available on Tesla products
- Dual Copy Engines
- They allow you to extend dual buffer to use multiple streams
- Streams basically allow for N independent kernels to be executed in a pipeline fashion.
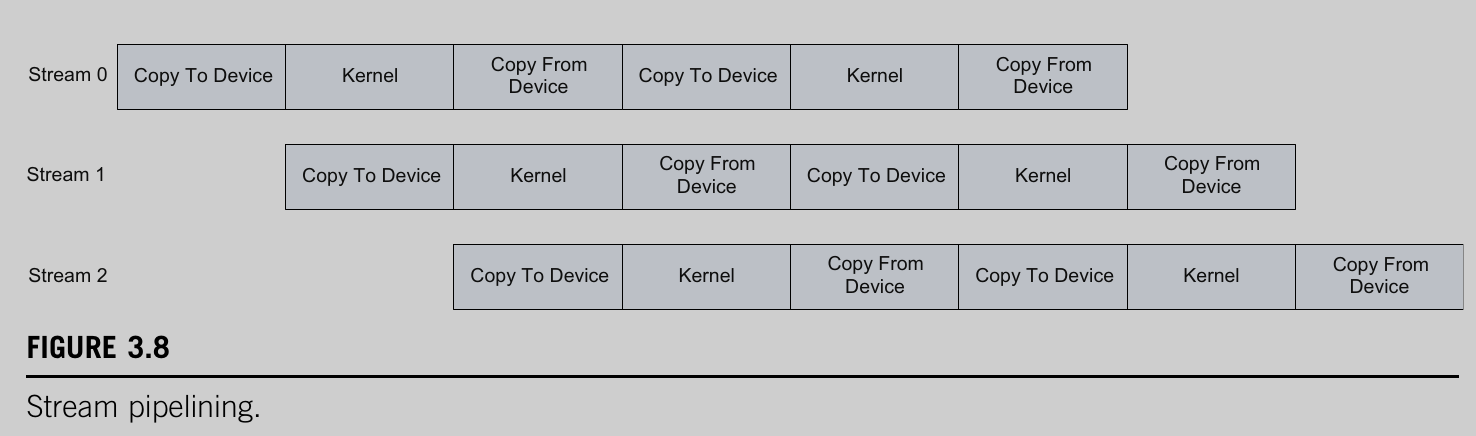
- Shared memory changed drastically in this version
- It was transformed into a combined L1 cache.
- For backward compatibility, a minimum of 16KB must be allocated to the shared memory. Thus L1 cache is really only 48K in size.
- Using a switch, shared memory and L1 cache usage can be swapped, giving 48K shared memory, and 16K L1 cache.
- Alignment requirements became stricter
- A cache line size of 128 bytes is the norm now
- If you have a sparse and distributed memory pattern per thread, you need to disable this feature and switch to the 32-bit mode of cache operation.
- Shared memory banks from 16 to 32 bits
- Allows each thread of current warp to write to exactly one bank of 32 bits in the shared memory without causing a shared bank conflict.
Compute 2.1¶
- 48 CUDA cores per SM instead of usual 32 per SM
- 8 single precision, special function units per SM instead of usual 4
- Dual warp dispatcher instead of usual single warp dispatcher
- Warps, are groups of threads.
- On 2.0, single-warp dispatcher takes two clock cycles to dispatch instructions of an entire warp
- On 2.1, we now have four instruction dispatchers instead of 2.
- This hardware is a superscalar approach, similar to what is found on CPUs.
- This version is a significant divergence from the universal Thread level Parallelism(TLP) used till this point, and now the focus was being shed on ILP
- ILP required the instructions to be independent of one another.
Chapter 4 -- Setting up CUDA¶
¶
¶
¶
Chapter 5 -- Grids, Blocks and Threads¶
- NVIDIA chose SPMD (Single Program, Multiple data) for scheduling. A variant of SIMD.
- a single flow of execution through the program.
- The CUDA Programming model groups threads into special groups it calls warps, blocks and grids.
Threads¶
- Fundamental building block of a parallel program
- SFR(Split Frame Rendering) type splits as coarse-grained parallelism
- Large chunks of data are split in some way between N powerful devices and then reconstructed later as processed data.
- Similar to macro and micro there is coarse and fine-grained parallelism.
- Fine-grained parallelism is usually found at the programmer level on devices that support huge number of threads such as GPU.
- CPUs follow MIMD(Multiple Instruction Multiple Data) model.
- This is a more flexible approach but incurs additional overhead in fetching multiple independent instructions.
CPU vs GPU¶
- GPU
- GPUs are designed for running a large number of simple tasks
- GPUs also use the same concept of context switching but instead of having a single set of registers, they have multiple banks of registers.
- A context switch here involves setting a bank selector to switch in and out of the current set of register.
- This is much faster than having to save to RAM.
- GPUs are designed to handle stall conditions.
- GPU model is a data-parallel one and thus needs thousands of threads to work efficiently.
- When it hits a memory fetch or has to wait for result of calculation, the streaming processor simply switch to another instruction stream.
- Then the Streaming Processor returns to the stalled instruction some time later.
- GPUs calculate 32 per Streaming Multiprocessor
- CPU
- Context switching on CPU is expensive.
- CPU often run single-thread programs
- they calculate just a single data point per core, per iteration.
Task Execution Model¶
- Groups of N Streaming Processors execute in a lock-step basis.
- Running the same program but on different data.
- Because of the huge register file, there is effectively zero overhead.
- What does lock-step basis mean?
- Each instruction in the instruction queue is dispatched to every SP within an SM.
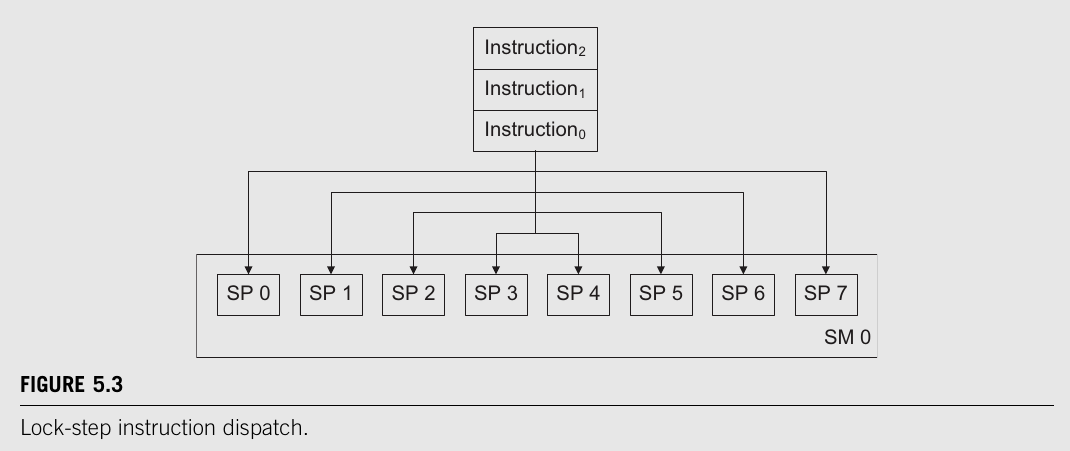
- An SM is like a processor with N Cores (SPs) embedded within it
- Each instruction in the instruction queue is dispatched to every SP within an SM.
- If the program does not follow a nice neat execution flow where all N threads follow the same control path, you will require additional execution cycles.
- If some part of the data takes a different path, then the other SPs in the warp will have to stall till the other branch is executed in a later cycle.
- When all the instructions for all branches are executed is when the GPU would return the data for the Warp.
GPU Structure Hierarchy¶
- Grid ->
gridDim.x,gridIdx.x - Block -->
blockDim.x,blockIdx.x - Warp
- Thread -->
threadIdx.x
Threading on GPUs¶
- Loop parallelization
- when there is no dependency between one iteration of the loop and the next.
- Each thread on a GPU handles only 1 or a few indexes of the loop.
- In CUDA,
- you translate the for loop by creating a kernel function.
- the programming model states that all serial code execution should be done by CPU only, and parallel code by GPU.
- Keywords
- a
__global__prefix is added to the C function that tells the compiler to generate GPU code. thread__idxis a structure which holds the information about the thread.threadIdx.xgives value for current thread index
kernel_function <<<num_blocks, num_threads>>>(param1, param2, ...)num_blocks--> Ensure that there is at least onenum_threads--> simply the number of threads that you want per block
threadIndex = (blockIdx.x * blockDim.x)+ threadIdx.xwarpSize-> builtin variable given by NVIDIAdim3-> special CUDA type to create a 2D layout of threadsdim3 threads_rect(32,4)dim3 blocks_rect(4,1)kernel_func<<<blocks_rect, threads_rect>>>(a,b,c)
gridDim.x-> size in blocks of the X dimension of the grid- similarly
gridDim.y
- similarly
blockDim.x-> size in threads of the X dimension of a single block- similarly
blockDim.y
- similarly
- a

idx = blockDim.x * blockIdx.x + threadIdx.xidy = blockDim.y * blockIdx.y + threadIdx.ythreadIndex = ((gridDim.x * blockDim.x) * idy) + idx
Hardware¶
- You actually only have N cores on each SM
- When all 32 threads are waiting on something such as memory access, they are suspended.
- Warp --> 32 Threads
- Half-warp --> 16 Threads
- 128 threads -> 4 warps of 32 threads in each warp
- When all 32 threads in a warp are suspended, the hardware switches to another warp.
- GPU continues in this manner until all warps have moved to the suspended state while moving the ready warps to execution.
- In practice, multiple blocks are run on each SM to avoid any idle states.
Blocks¶
blockIdx.xholds the value which is the index of the current blockblockDim.xhold the number of threads you requested per block.The limit of parallelism is only really the limit of the amount of parallelism that can be found in the application.
- Assuming one threads per array element, you can process up to 64 million elements with 64 million threads.
- Why use blocks and not just summon (invoke) many threads directly instead?
- More blocks give more efficiency and scalability
- GPU have Maximum threads per block, if GPU uses some threads most of GPU remains idle
- When you divide into blocks, more of the GPU's SMs work simultaneously on the task.
- The larger the thread block, more potential you have to wait for a slow warp to catch up.
Grids¶
- A set of blocks where you have X and Y axis, to create a 2D array like effect.
- This mapping gives us in total
X * Y * Tnumber of total threads. - The number of threads in a warp should always be a multiple of warp size.
- You can only schedule full warp on hardware, 32 threads or nothing.
- The remaining part goes unused, or even worse the unknown data there is used, ensure you don't process elements off the end of the X axis by adding an edge case condition.
Stride and Offset¶
- Thread blocks can be thought of as 2D structures.
- Width of the array is referred to as stride of the memory access.
- address calculation :
(row * (sizeof(array_element) * width)) + ((sizeof(array_element) * offset) - The width of the array must ideally be always a multiple of warp size.
- Thread within the same block can communicate using shared memory
Warps¶
- The basic unit of execution on the GPU
- Warps on GPU are currently 32 elements, but they might be increased in future thus NVIDIA recommends using the variable
warpSizethan hardcoding
Branching¶
- Branching causes a divergence in the flow of execution.
- Threads that take the branch are executed, others that do not are marked as inactive.
- Once taken branch is resolved, the other side of the branch is executed, until the threads converge once more
- Hardware can only fetch a single instruction stream per warp.
- Solution? If you can arrange the divergence to fall on half warp (16-thread) boundary, you can actually execute both sides of the branch condition.
GPU Utilization¶
- Compute 3.0 -> Kepler
- Only consistent value that gets you 100% utilization across all levels of the hardware is 256 threads.
- For max compatibility, you should aim for either 192 or 256 threads.
Block Scheduling¶
- SM can accept upto 8 blocks, depending on block size typically 6 to 8.
- As all blocks are of the same size, any block in the list of waiting blocks can be scheduled in the SM
- on a GPU, multiple runs on the same data can result in different but correct answers.
- Since the result is different that before, doesn't make it incorrect.
Basic Concept of Histograms in Programming¶
- A histogram counts the distribution of data across bins (e.g., 256 bins for values 0-255).
- A serial implementation loops through an array and increments the corresponding bin.
Parallelization Problem¶
- In a parallel implementation, multiple threads may try to update the same bin at the same time.
- This leads to a race condition, where multiple threads fetch, increment, and write back the same bin value simultaneously, losing increments.
CUDA Solution: Using Atomic Operations¶
- Atomic operations ensure that each update to a bin happens sequentially, avoiding race conditions.
atomicAdd(&value, 1);guarantees that no two threads increment the same bin at the same time.
Performance Issues with Atomic Writes¶
- Using one thread per input element leads to high contention for the 256 bins, slowing down execution.
- Example: With a 512 MB array, each bin might have 131,072 threads competing to update it.
- The naive approach achieves poor performance (~1025 MB/s) due to memory bandwidth limitations and atomic write contention.
Optimization Using Data Decomposition¶
- Improving Read Efficiency
- Instead of reading 1 byte per thread, read 4 bytes (32-bit integer) per thread to improve memory coalescing.
- This does not improve speed significantly because the atomic writes remain a bottleneck.
- Using Shared Memory for Histograms
- Instead of writing directly to global memory, each Streaming Multiprocessor (SM) first accumulates histogram values in fast shared memory.
- Once all threads in a block finish updating shared memory, results are written back to global memory in a single step, reducing contention.
- This improves performance 6× (6800 MB/s).
- Processing Multiple Histograms per Block
- Instead of computing one histogram per block, compute N histograms per block to reduce the number of global memory writes.
- This further improves performance, peaking at 7886 MB/s for N=64 on a GTX460 card.
Key Takeaways¶
- Atomic operations solve race conditions but create performance issues.
- Using shared memory before writing to global memory improves performance significantly.
- Batch processing (processing N histograms per block) further optimizes global memory bandwidth usage.