Lexical Analysis
---¶
Curriculum concepts:¶
- Concept of Lexical Analysis, Regular Expressions, Tokens, Lexemes, and Patterns, Block Diagram of Lexical analyser, Revision of finite automata, Introduction to LEX Tool and LEX file specification, Error detection and recovery in LEX.¶
Role of Lexical Analyzer:¶
- Read input characters from
srcprogram, group into lexemes and produce as output a sequence of tokens for each lexeme in source program. - Parser calls the lexical analyzer to get tokens.
- Stripping out comments and white-space, correlating error messages generated by the compiler with the
srcprogram are some of the tasks performed by lexical analyzer. - Lexical Analyzer is divided into two processes:
- Scanning - comment deletion, white space compaction
- Lexical Analysis - sequence of tokens produced here
Tokens, Patterns and Lexeme:¶
- token -
<token_name, attribute_value>stored in symbol table.attribute_valueis optional. Parser processes the token_name symbols. - Pattern is a description for the acceptable lexeme form. Example,
number -> [0-9]*[\.[0-9]]?the REGEX accepts floating point and integer numbers. - lexeme -> sequence of characters that matches the pattern for a token and is identified by lexical analyzer.
Input Buffering¶
- To get the lexeme, we often have to look ahead of the current lexeme to match the pattern.
- A two-buffer scheme handles large lookaheads.
- Two buffers each of size n are loaded to save time; save time? Yes, from having to read from a buffer and waiting for the next buffer. Solution, pre-fetch and have two buffers.
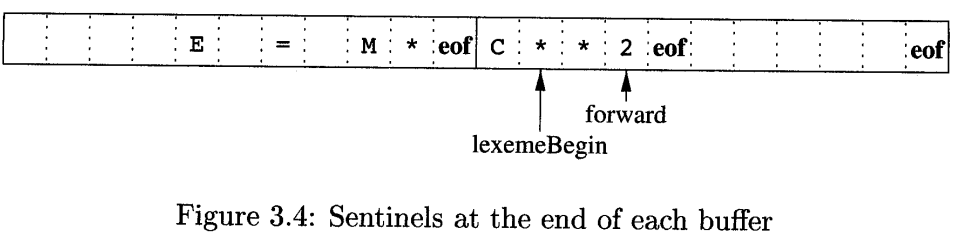
- If eof occurs at the end of buffer, it denotes end of buffer. If eof occurs anywhere else it denotes end of the input.
- Sentinels
- The sentinel is a special character that cannot be part of the source program - eof.
- For each character read we have two tests
- Is end of buffer?
- What character is read?
Terms for Parts of Strings¶
- \(prefix\) \(\rightarrow\) remove 0 or more symbols from the end of string
- \(suffix \rightarrow\) remove 0 or more symbols from the beginning
- \(substring\rightarrow\) string after deleting any prefix/suffix
- \(subsequence\rightarrow\) string after deleting 0 or more not necessarily subsequent characters (deleting any characters in the string)
- \(proper\ prefix/suffix/substring\rightarrow\) not \(\epsilon\) or not equal to the original string.
Regular Expressions¶
- Built recursively out of smaller REGEX
- Each regular expressions \(r\) denotes a language \(L(r)\)
- Algebraic Laws for Regular Expressions!
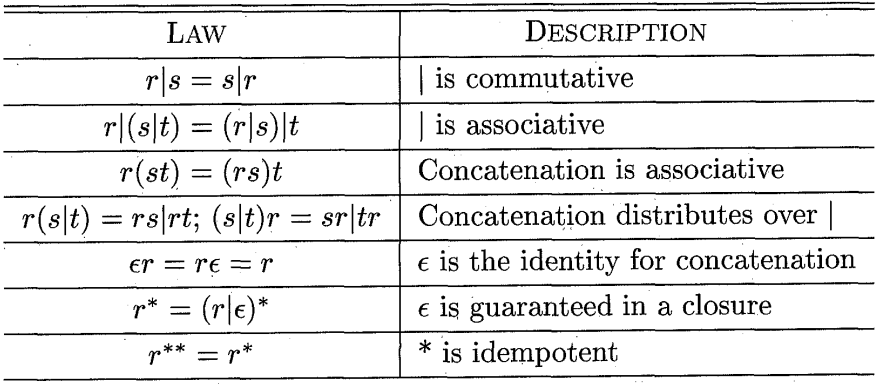
- Extensions of REGEX:
- One of more instances \(r^{+}\)
- \(a^{+}\) is {a,aa,aaa,aaaa,...}
- Zero or one instance \(r?\)
- \(a?\) is {\(\epsilon\) | a}
- Character classes \([a_1a_2...a_n]\)
- \([abc]\) \(\leftrightarrow\) \(a|b|c\)
- \([a-z]\) \(\leftrightarrow\) \(a|b|...|z|\)
- One of more instances \(r^{+}\)
- Normal strategy is to take the longest prefix of the input that matches any pattern as a lexeme.
Transition Diagrams¶
- Collection of nodes/circles called states.
- Each state represents a condition that could occur during the process of scanning the input looking for a lexeme that matches one of several patterns.