Topics For endSem
1. Distributed System Features¶
- Resource Sharing - sharing hardware, software and data
- Scalability - Horizontal and vertical
- Fault Tolerance -
- Transparency - Hide complexity from users, and seem like a unified system
- Concurrency - simultaneous/concurrent execution of tasks across processors
- High integrity / Openness -
- Security
- Heterogenity - Support across diverse hardware/software
- High availability
- Load Balancing - Distribute load to avoid a single node becoming bottleneck
- Communication - TCP/IP, RPC
- Performance
2. Client Server Model¶
- Process offering services (servers)
- Processes that use services (Clients)
- Request-Reply model
- Client-Network-Server
- Advantages
- Centralized Management
- Scalability
- Specialization - Servers do specific jobs and are optimized for them
- Data Security
- Ease of Maintenance
- Disadvantages
- SPOF
- Cost
- Scalability (Clients \(\uparrow\) , servers act as bottleneck)
- Network Dependency
3. TCP/IP Model¶
4. Clock Synchronisation¶
- Distributed Systems
- Internal (Mutual)
- Need
- Correct results
- Measuring duration of distributed activities
- Need
- External (With Real time clock)
- Internal (Mutual)
- A set of clocks are said to be synchronized if the clock skew of any two clocks in this set is less than some specified constant .
- time must never run backward.
- Externally synchronized clocks are also internally synchronized, but the converse is not true.
- Algorithms
- Centralised -> One node (time server node) has real time receiver
- Distributed Algorithm -> Each node has a real time receiver for external synchronization
- Internal communication for internal synchronisation
Passive Time Server Algorithm¶
- Time = \(T\ +\ (T_1\ -\ T_0)\ / 2\)
- Node sends a message at time \(T_0\)
- Time Time server responds with current time T
- Node readjusts the message using above given formula, \(T_1\) is time it receives reply from time server
- Active Time Server Algorithm
- Time server periodically broadcasts its clock time T
- \(T\ +\ T_a\) to get the current time, \(T_a\) is predefined time.
Distributed Time Service¶
- Each node is either a DTS Client or DTS Server
- To sync clock, DTS Client makes requests to DTS Servers
- Uses method of intersection for computing ne clock value and resets ts clock to this value.
- As we are finding intersecting time frames here to set for all clocks, it is recommended for each LAN to have at least 3 DTS Servers
- DTS servers of a LAN also communicate among themselves periodically and use the same algorithm to keep their clocks mutually synchronized.
6. Communication Protocol¶
- Group Communication
- The basic goal of communication protocols for network systems is to allow remote computers to communicate with each other and to allow users to access remote resources
ISO/OSI Reference Model¶
- A guide, not a specification, a theoretical model
- Seven Layers - Application Presentation Session Transport Network Data-Link Physical
ISIS Routing Protocol¶
- Each router has copy of the entire topology
- IS-IS protocol facilitates efficient communication in distributed networks
- Shortest Path | Scalable Level 1,2(Backbone routers), 1/2
Asynchronous Transfer Mode (ATM)¶
- Voice video data sent along the same network
- data transfer in discrete chunks, fixed sized packets (Cells)
- ATM’s high performance, scalability, traffic integration, QoS support, and reliable transmission make it an attractive technology for distributed systems.
7. Lamport’s Algorithm – Physical and Logical¶
- uses - happened-before notation | a -> b , a happened before b
- It is a transitive relation a->b, b->c, then a->c
- concurrent events | casually ordered events
- receiver clock < message timestamp?
- set system clock to
message timestamp + 1 - else, do nothing
- set system clock to
- Each message carries a timestamp of the sender's clock
- sending
- time = time+1
- time_stamp = time
- send(message, time_stamp)
- receiver side
- message,time_stamp -> received
- time = max(time_stamp, time)+1
8. FIFO Algorithm¶
9.Dijkstra’s Algorithm¶
- Shortest path from one node to every other node
- A table to keep track of distances
- Distances measuring are from starting node, initialise table with all node values as infinity and start point as 0
- Update via edges leaving start poiint
- Pick the smallest edge of the vertex that hasn't been chosen.
- Repeat till end
- \(O(|E| + |V| log|V|)\)
10. Kruskal's Algorithm¶
- Steps
- Sort edges by ascending weight of edges
- Pick the smallest weighing edge, that does not result in a cycle or previously visited nodes.
- Keep doing this until all nodes are in the same tree
- O(E Log E)
11. Remote Procedure Call¶
- Interprocess communication mechanism for distributed systems
- Extension of
Procedure call mechanism - uses client-server model.
- Requesting program is client
- Service providing program is the server
- Client Stub -> Proxy for remote procedure
- Server stub -> corresponding point of access to client stub
- Caller sends a requests to server and blocks till the reply message
- Key Components of RPC:
- Client Side : Client -> Client Stub -> RPCRuntime
- Server Side : RPC Runtime -> Server Stub -> Server
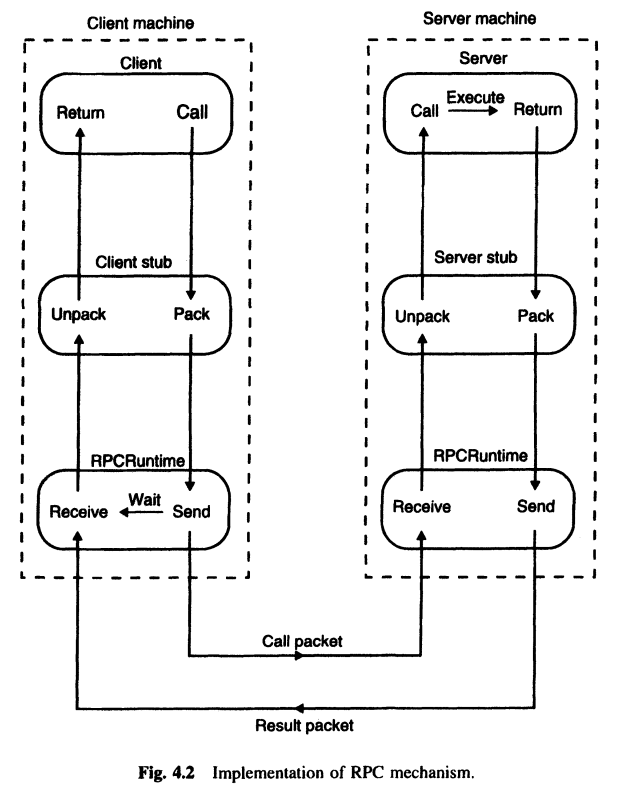
- Client is completely unaware of the fact that the process is being executed on a different machine. It's just another interprocess communication for it.
14. Mutual Exclusion in Distributed Systems¶
- Requirements for Mutual Exclusion Algo
- At any given time, only one process should access a given resource.
- No Starvation for any process should be there
- Approaches
- Centralized
- A coordinator process coordinates entry for critical sections
- process requests to coordinator, coordinator grants permission to execute its critical section code, by using some scheduling algorithm
- Only one process at a time
- Process notifies coordinator after exiting the critical section
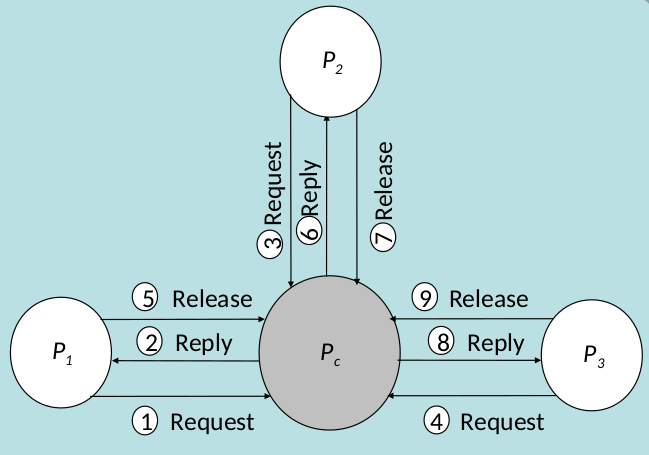
- FIFO ensures no starvation
- Three messages per critical section entry
- Request | Reply | Release
- Drawbacks
- SPOF
- Performance Bottleneck
- Distributed
- When a process wants to enter a critical section, it sends a request message to all other processes.
- The message contains
- the process- id
- the critical-section-id
- timestamp generated by the process
- A process enters the critical section as soon as it has received reply messages from all processes
- After exiting from the critical section, it sends reply messages to all processes in its queue and deletes them from its queue
- If a process also wants to get into the critical section, the process with the earlier timestamp value executes first
- Disadvantage:
- n points of failure, if a node fails there is no way get reply from all nodes
- Token passing
- Circular logical ordering of nodes
- token passed to one at a time, to the next neighbour
- Process receiving the token can either execute its critical section, and/or pass the token to the next neighbour
- Centralized
15. Deadlocks in Distributed Systems¶
- A state of permanent blocking of a set of processes due to unmet dependency resolution
- Necessary Conditions for a deadlock
- Mutual Exclusion
- Hold-and-wait
- No-preemption
- Circular Wait
- Deadlock Modelling
- Resource Allocation Graph
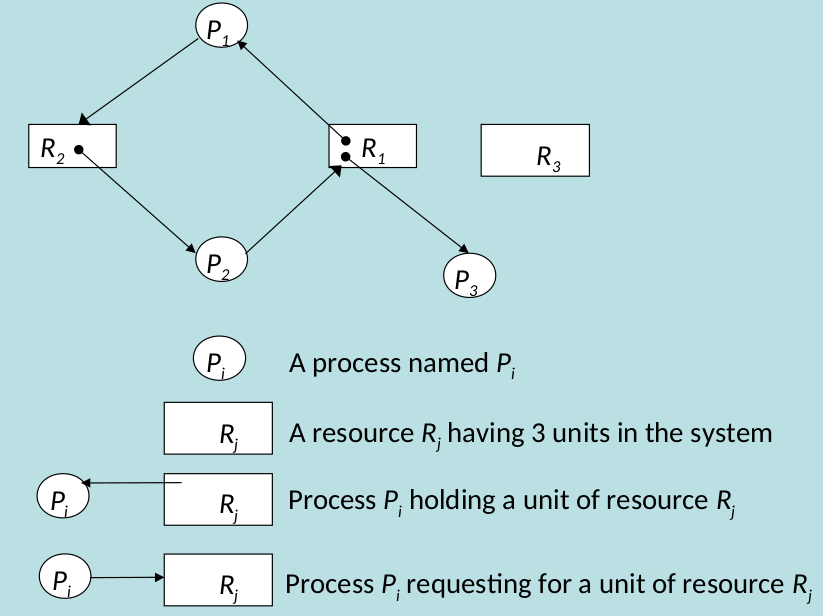
- \(R_i \rightarrow Pi\) - Resource is being used by \(P_i\)
- \(Pi \rightarrow R_i\) - \(P_i\) is waiting for resource
- Resource Allocation Graph
- If only once unit of each resource type in the system, a cycle is necessary and sufficient for a Deadlock
- If one or more resource types in the cycle have more than one unit, a knot is sufficient
- Wait For Graph
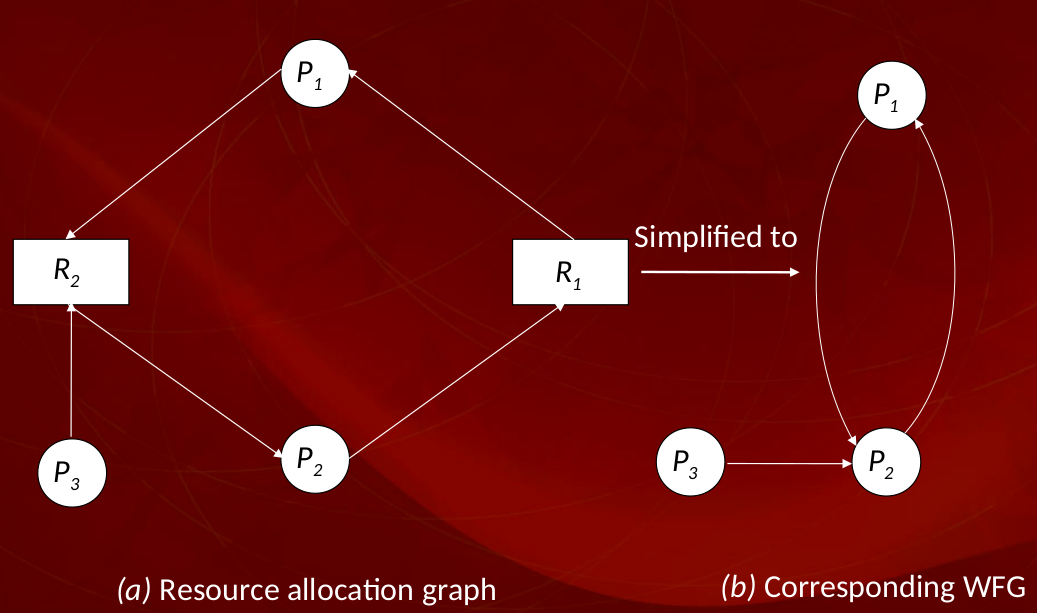
Methods for Handling Deadlocks¶
- Avoidance
- Safe and unsafe state analysis is done before allocating a resource
- system checks to find out if this allocation will change the system state from safe to unsafe.
- If no, the request is immediately granted, else it is deferred.
- Disadvantage
- Requires Advanced knowledge of resource requirements
- Assumes no of processes competing for allocation is known and fixed
- degrades system performance
- Prevention
- Collective Requests - tackles Hold and wait condition
- Ordered Requests - tackles circular wait situations
- Preemption - Tackles No preemption
- Spooling outputs onto a disk file, from where the process requiring mutual exclusion reads - Tackles Mutual-exclusion
- Detection & Recovery
- Maintaining a WFG, checking for Cycles in WFG. If Cycle, then Deadlock
- Recovery Methods
- Operator Intervention
- Termination of Process
- Rollback of Process
- WFG in a distributed Environment\
- Construct Resource Allocation Graph for each site
- Convert Resource allocation graph to WFGs
- Take union of the WFGs of all sites, to get one single global WFG
- The three commonly used techniques for organizing the WFG in a distributed system are:
- Centralized
- local coordinator and central coordinator - solve respective deadlocks
- WFG information from local to central coordinator transferred as follows:
- Continuous transfer
- Periodic Transfer
- On-request Transfer (of Central coordinator)
- Hierarchical
- a logical hierarchy of deadlock detectors (controllers)
- Each leaf node -> Local WFG
- Each Inner Node -> Union of all child WFGs
- Lowest level that finds a cycle, solves it
- Distributed
- WFG Based
- Each site has local WFG
- An extra node is added to model Waiting situations
- \(Edge(P_i,P_{ex})\) if process \(P_i\) is waiting for a resource in another site being held by any process.
- Else vice versa
- A cycle in a local WFG that does not involve Pex indicates a local deadlock, and resolved locally.
- Else, the affected site sends a message to the appropriate site, and the appropriate site restarts.
- The local site with A outgoing \(P_ex\) node requests fo
- Probe Based
- Process fails to get a requested resource, it times out
- It then generates a probe message and sends to the process holding the resource
- Message has 3 fields
- Id of process just blocked
- Id of process sending this message
- Id of process to which message is being sent
- On receiving this message, if recipient is using the resource, it ignores the message
- If recipient is waiting for the resource, it forwards the message by updating the second and third field.
- After repeating the process, if the message gets back to the original process who sent the message, there is a cycle, thus a deadlock in the system.
- WFG Based
- Centralized
16. Logical Clocks and Physical Clocks¶
Lamport's Logical Clocks¶
- order in which events occur matters here
- If a and b are two events in the same process, and a comes before b, then a → b.
- Happened Before Events
- Timestamp of event A should Always be less than Event B, A -> B
- There are two types of events
- Casually ordered Relation - A -> B
- Concurrent Event - A || B
- If two events are not related by the happened before relation, they are said to be concurrent
- Lamport's Algorithm for labelling concurrent events
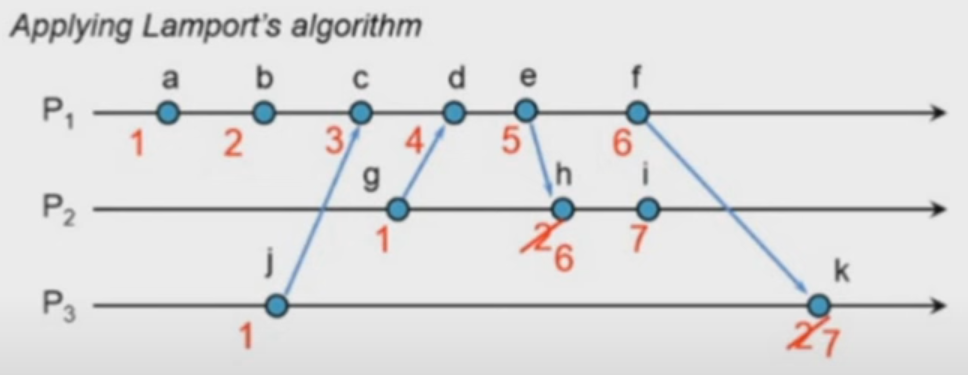
- Logical Clock Implementations
- Counters
- Physical Clock
- Counters

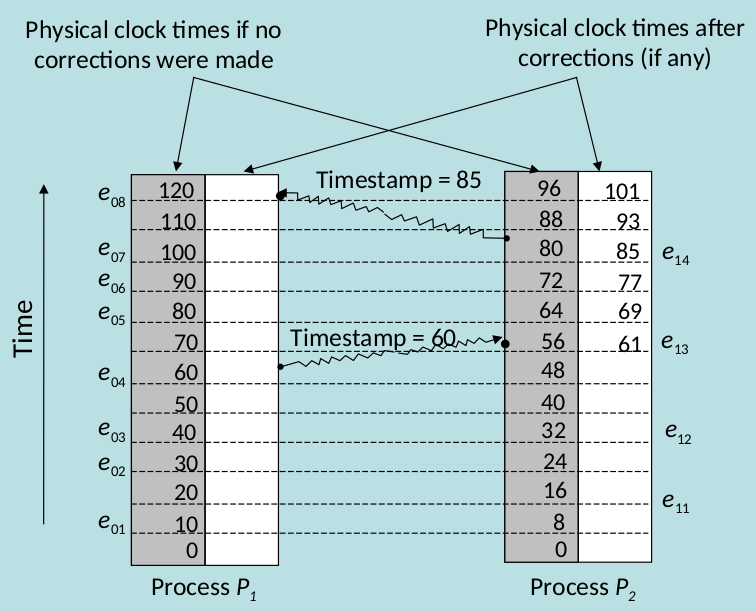
Physical Clocks¶
- Sometimes we simply need the exact time, not just an ordering.
- Electronic device that counts oscillations in a crystal at a particular frequency
- Quartz crystal, Constant Register, Counter Register
- Clock Synchronisation - The goal is to keep the deviation between two clocks on any two machines within a specified bound, known as the precision π:
- Internal synchronization: keep clocks precise
- External synchronization: keep clocks accurate
- Clock Drift - clock comes with a specified maximum drift rate.
- Clock Drift over the time is known as skew
17. Distribution System Architecture¶
18. Election Algorithms¶
- An algorithm requires some process to act as a coordinator. Election Algorithms help in selection of them dynamically.
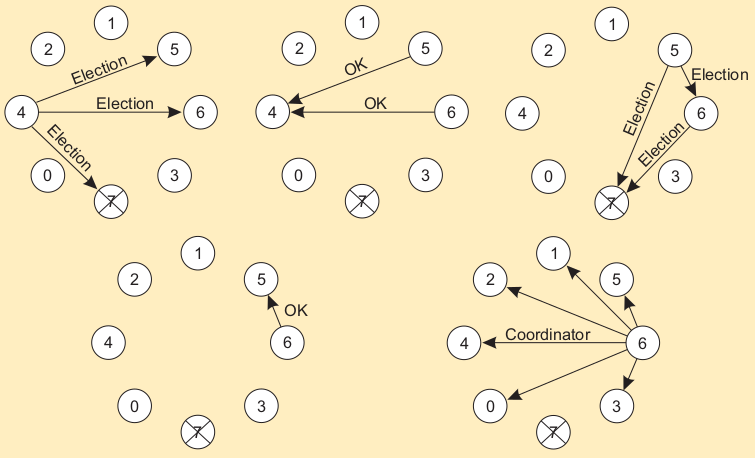
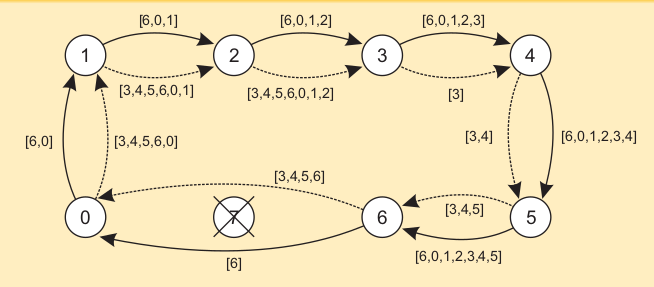
1. Bully Algorithm¶
- All processes have an identifier value (id | priority number)
- A process \(P_k\) notices that coordinator is not responding, it initiates an election
- \(P_k\) sends ELECTION message to all higher ids than itself
- If No one responds -> \(P_k\) wins the election and becomes coordinator
- If any higher up responds, it takes over and higher up repeats the process
Election in a Ring¶
- Process priority is obtained by organizing processes into a (logical) ring.
- Process with the highest priority should be elected as coordinator.
- The initiator sends a coordinator message around the ring containing a list of all living processes.
- The one with the highest priority is elected as coordinator.
19. Workstation, Processor Pool and Hybrid Model¶
Workstation Model¶
- workstations scattered throughout a campus connected by a high-speed LAN
- Diskful(with local disks) ,
- Disks -> Used in four ways
- Paging, temporary files,
- ... + system binaries,
- ... + file caching
- Complete Local file system
- Reduced network load
- Disadvantages
- Higher cost due to large number of disks
- Cache-consistency problems
- Disks -> Used in four ways
-
Diskless
- Why Diskless? file system must be implemented on remote servers
- These tend to be cheaper
- backup/maintenance is cheaper
- no fans and noises
- provides symmetry and flexibility
- Use any machine to access files via remote servers.
- Advantage:
- Low cost | Easy Hardware, software Maintenance
- Symmetry | Flexibility
- Disadvantage
- Heavy Network Usage | File server -> bottleneck
- Why Diskless? file system must be implemented on remote servers
-
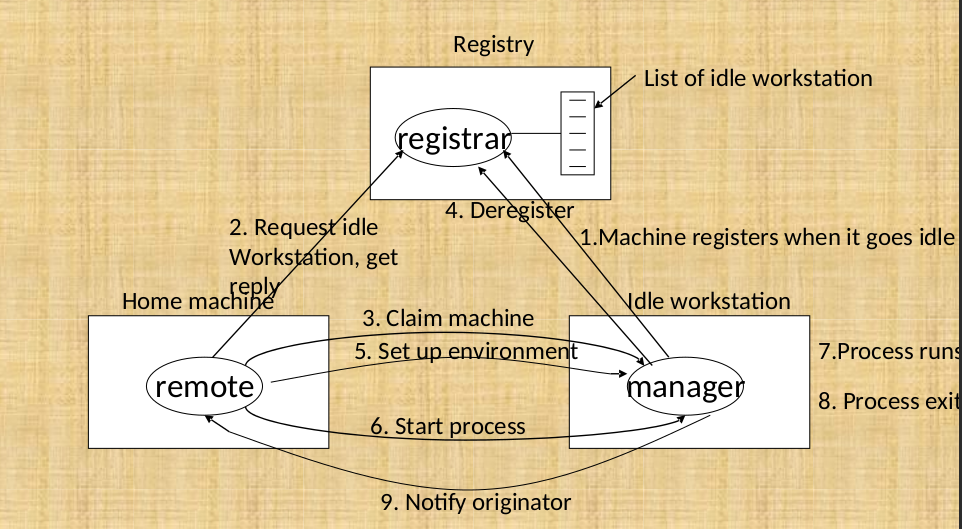
Idle Workstations - used by active users to perform tasks
- Algos to locate idle workstations
- Server Driven - server registers itself in a registry file or a public broadcast
- Client Driven - Client broadcasts request for resource
- Server Driven - server registers itself in a registry file or a public broadcast
Processor Pool Model¶
- a rack full of CPUs in the machine room, dynamically allocated to user as per the demand
Hybrid Model¶
- Each user gets their personal workstation and a processor pool is addition
- Even if the processor is not allotted due to high load, you still have the workstation to do the work.
20. Distributed Shared Memory¶
21. Event-Driven and Time-Triggered System¶
Event-triggered Real-time system¶
- a significant event in the outside world detected by some sensor causes an interrupt in the attached CPU.
- These systems are interrupt driven
- May fail under conditions of heavy load (multiple events happening at once.)
- Faster response at low load, more overhead and chance of failure at high load.
- Dynamic Scheduling is good for Event triggered systems.
- Not much advance work, scheduling happens on the go.
- Make better use of resources than static scheduling.
Time-triggered real-time¶
- a clock interrupt occurs every T ms
- At every clock tick, sensors are sampled and actuators are driven.
- No interrupts other than clock ticks.
- T must be chosen carefully
- Too small, high interrupts, context switching less CPU usage
- Too High, significant events may go unnoticed.
- suitable in relatively static environment, where a great deal is already known about system's behaviour.
- Static Scheduling is good for this system type, why? read on..
- Schedule must be carefully planned in advance, with effort going into choosing various parameters
- Wasting resources (heavy calculations to make this apriori schedule) is often the price that must be paid to guarantee that all deadlines are met
- Optimal/near optimal schedule for a time-triggered system.
Common for both types of systems¶
- Predictability - behaviour should be predictable
- Fault-tolerant real-time systems must be able to cope with the maximum number of faults and the maximum load at the same time.
- Language Support -( Coding Language) The selected language should have following properties
- max execution time for every task can be computed at compile time.
- language cannot support while loops and recursion
- It should be able to deal with time itself
- a way to express minimum and max delay
- exception handling capabilities
- periodic event statements
- max execution time for every task can be computed at compile time.
Real Time Communication¶
- Can't use ethernet (not predictable)
- Token ring LAN is predictable