Introduction & Modeling Concepts
- Computer Architecture consisting of interconnected, multiple processors are:
- Tightly coupled systems
- single, system wide primary memory (address space)
- Communication between processes take place using shared memory
- Parallel processing systems
- Loosely coupled systems
- No shared memory. Local memory per processor
- Message passing is done across network for communication between processors
- Distributed (computing) systems
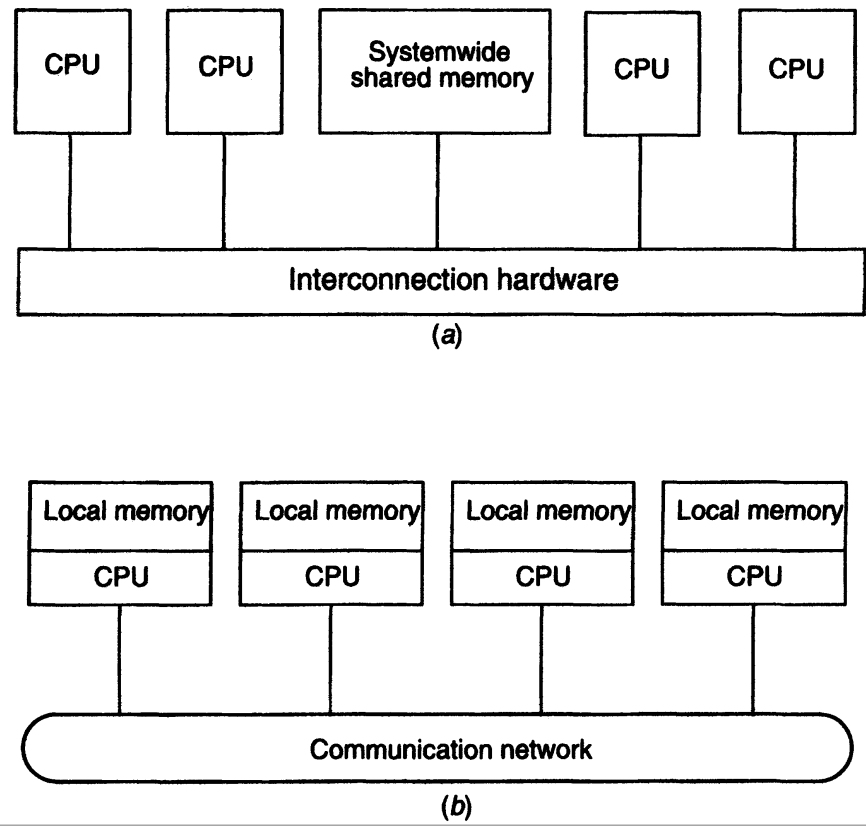
- Tightly coupled systems
Distributed System¶
- A collection of independent computers that appears to its users as a single coherent system
- No machine has complete information about system state
- Machines make decision based on local information
- Failure on One machine doesn't pull down the system
- No implicit assumption that a global clock exists.
Types of Distributed Systems¶
- Computing Systems
- High Performance Computing (HPC)
- Information Systems
- Transaction Processing Systems (TPS)
- Enterprise Application Integration (EAI)
- Pervasive Systems
- Ubiquitous Systems
Cluster Computing Systems¶
- Excellent for parallel computing & can serve as a super computer
- Collection of similar workstations/PCs, closely connected by means of a high-speed LAN.
- Each node runs the same OS; this creates an homogeneous environment.
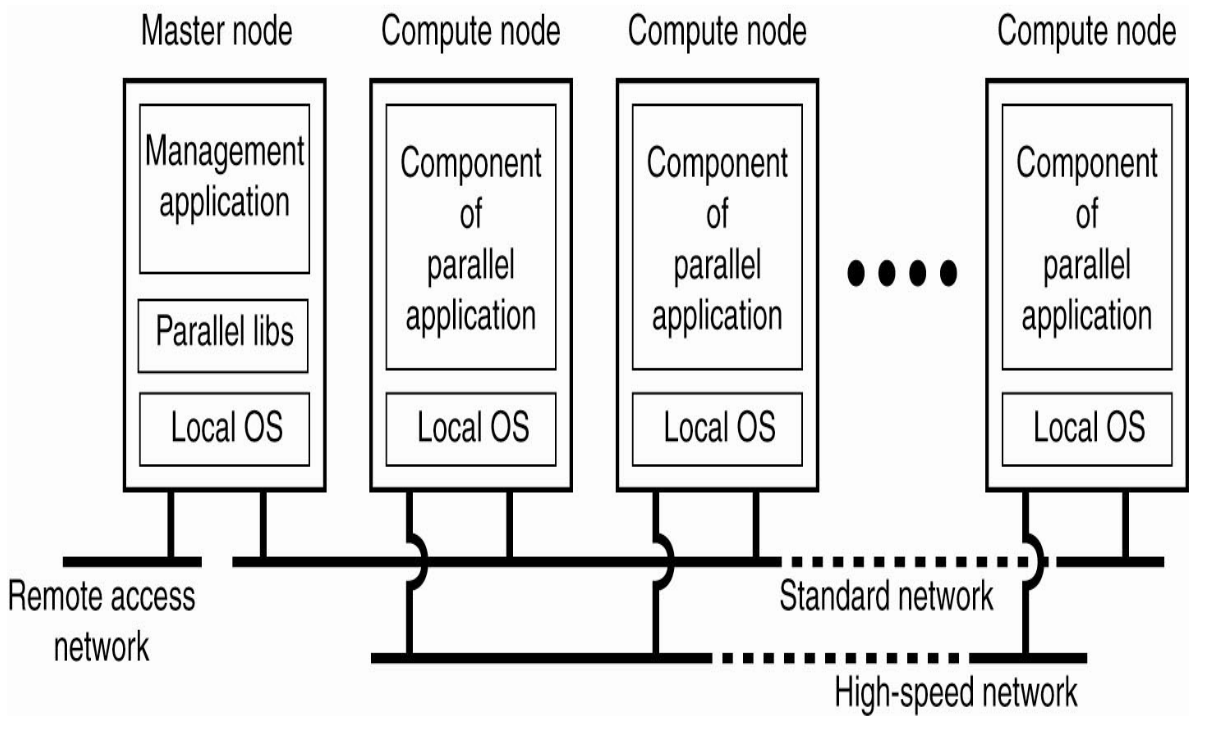
- Shared Storage between k Nodes(Clustered Servers) which are in turn accessed by n computers/networking devices.
- 1 Master Node, n Compute Nodes
- Master Node has Management Application and Parallelization libraries
- Compute Nodes act like components of Parallel applications - they complete their alloted tasks and return the result.
- Master node has to merge and make sense of the results that it had distributed among its Compute Nodes
- Architecture of Clustered Nodes
- Configurations (2 Types)
- Standby server with no shared disk (Hot-server)
- If master goes down, the standby server is promoted to master and admin are notified
- Standby server with no shared disk (Hot-server)
Distributed Computing System Models¶
Mini computer Model¶
- Extension of centralized time-sharing system
- Few mini computers interconnected by a communications network.
- Each mini computer has several users working on it actively, thus multiple terminals per mini computer.
- Useful when resource sharing with remote users is desired
- Example, ARPAnet[^1] is based on minicomputer model
Workstation Model¶
- several individual workstations interconnected by a communication network.
- Each workstation equipped with its own disk and serving as a single user computer
- E.g. Cognizant (College) lab PCs connected together over LAN
- Idle workstations can be used by workstations on which users have logged on.
- User logs onto a workstation -> his "home" and submits jobs for execution
- If system finds that user's workstation does not have sufficient processing power for executing process efficiently, it transfers one or more of the processes from user's workstation to currently idle workstations.
- Issues
- Identifying Idle Workstations
- Process transfer from "home" to idle workstation & execution.
- What happens to a remote process if a user logs onto a workstation that was idle till now & being used for execution? Approaches:
- Allow remote process to share resources of workstation along with current logged in user.
- This defeats the main idea of workstations serving as personal computers though, the logged-on user does not get his or her guaranteed response.
- Kill the remote process. But the progress is lost, file system might be left in an inconsistent state
- Migrate remote process back to "home" workstation. Continue execution there. Hard to implement because it requires support for preemptive process migration facility.
- Allow remote process to share resources of workstation along with current logged in user.
Workstation Server Model¶
- Workstation model
- with its own local disk is diskful workstation
- without a local disk is diskless workstation
- Consists of few minicomputers and several workstations (mostly diskless, few diskful) interconnected by communication network
Processor Pool Model¶
- processor-pool model is based on the observation that most of the time a user does not need any computing power but once in a while he or she may need a very large amount of computing power for a short time
- The processors are pooled together to be shared by the users as needed
- No HOME machine, user logs in to the system as a whole.
- Compared to workstation model, better utilization of available processor hardware is provided
Hybrid Model¶
- Combines Processor pool model and Workstation server model
- Costlier to implement that either of the above models.
Why are Distributed Systems gaining popularity?¶
- Inherently Distributed Applications
- employee database updated at local office, needs to be accessed by main office and other offices.
- A compulsory need of a distributed system here.
- Information sharing among distributed users
- desire for efficient person-to-person communication facility by sharing information
- Computer Supported Co-operative working (CSCW) or groupware is when a group of users work cooperatively using distributed systems
- Resource Sharing
- software resources, hardware resources can be shared
- Better Price-Performance ratio
- Shorter Response Times and Higher Throughput
- Multiplicity of processors, distributed systems give better performance than single processor centralized systems
- Higher Reliability
- Reliability -> Degree of tolerance against errors and component failures
- Multiplicity of storage and processors ensures reliability
- Extensibility and Incremental Growth
- Better Flexibility in meeting users' needs
What is a Distributed Operating System?¶
- Two types of Operating Systems used by Distributed computing systems
- Network operating systems
- Distributed Operating Systems
- The above types are differentiated on the basis of the following:
- System Image
- The image of the OS from POV of the users.
- Network OS users see distributed systems as collection of different machines
- Distributed OS users are unaware of existence of different machines. (A virtual uniprocessor)
- Autonomy
- Fault Tolearance Capability
- System Image
- Definition
- A distributed operating system is one that looks to its users like an ordinary centralized operating system but runs on multiple, independent central processing units (CPUs). The key concept here is transparency. In other words, the use of multiple processors should be invisible (transparent) to the user
- The above definition is for a true distributed system\
- Completely true distributed systems are the ultimate goal of researchers working in the area of distributed operating systems
Issues in Distributed System Design¶
- Transparency (Hiding details from user)
- Access Transparency
- Location Transparency
- Name Transparency - resource name should not reveal hints about physical location
- User Mobility - User should be able to access a resource with the same name regardless of the machine a user is logged onto.
- Replication Transparency
- Failure Transparency
- Migration Transparency
- Concurrency Transparency
- Performance Transparency
- Scaling Transparency
- Reliability
- A fault is a mechanical or algorithmic defect that may generate an error.
- fail stop failure - system stops functioning
- Byzantine failure - system continues functioning but gives incorrect results. (More difficult to deal with)
- FAULT AVOIDANCE
- FAULT TOLERANCE
- Redundancy techniques
- Distributed Control
- FAULT DETECTION and RECOVERY
- Atomic Transactions (All or nothing)
- Stateless servers
- Acknowledgements and timeout based retransmissions of messages
- A fault is a mechanical or algorithmic defect that may generate an error.
- Flexibility
- Performance
- Scalability
- Heterogeneity
- Interconnected sets of dissimilar hardware or software systems needs data translation for interactions between two or more incompatible nodes.
- Security
- Emulation of existing OS
Summary¶
-
The main advantages of distributed computing systems are
- (a) suitability for inherently distributed applications
- (b) sharing of information among distributed users
- (c) sharing of resources
- (d) better price-performance ratio
- (e) shorter response times and higher throughput
- (f) higher reliability
- (g) extensibility and incremental growth
- (h) better flexibility in meeting users' needs.
-
Most important feature for open distributed systems
- Location Independence
- Cost effectiveness
- Reliability
- Scalability
- Security
- Readily Consumable
- Ex.
- Amazon EC2
- MS Azure
- Google Cloud
Foot Notes¶
- Buffering - Used to manage data flow
- Spooling - Data held in a temporary storage before being sent to some peripheral device (such as a printer from a program)