Introduction to Compiler Construction
Curriculum¶
- The role of language translation in the programming process, Translator Issues, Types of translators, Design of an assembler Introduction to phases of compilation, Front end and Back end model of compiler, Cross compiler, Incremental compiler.¶
Chapter 1 - Introduction¶
- Compiler - read
srclanguage -> translate to target language (e.g. machine language) while reporting errors during translation. - Interpreter - No translation. Direct execution of operations specified in src program on user inputs.
- Machine Language target program is faster
- Interpreter gives better error diagnostics
- Preprocessor - Collects source programs (modules) to build a single target program
- Linker - Resolves external memory addresses (code in one file might refer to a location in another file)
- Loader - Puts together all of the executable object files into memory for execution.
- Assembler - target program might be in assembly (easier to produce assembly and debug as well). Processed and relocatable machine code generated by assembler.
source program
|
v
**Preprocessor**
|
v
Modified source program
|
v
**Compiler**
|
v
Target assembly program
|
v
**Assembler**
|
v
Relocatable machine code
|
v
**Linker/Loader** <- Library files/ relocatable object files
|
v
Target Machine Code
Compiler Structure¶
- Two Parts
- Analysis (front end of compiler)
- Breaks up
srcinto chunks and imposes grammatical structure on them. - Detects if
srcis syntactically ill formed or semantically unsound[1^] and provides informative error messages for correction - Collects information about
srcand stores insymbol table[2^]. Passed to next steps along with intermediate representation created here.
- Breaks up
- Synthesis (back end of compiler)
- Constructs
targetprogram from intermediate + symbol table entries. Phases of a Compiler:
- Constructs
- Analysis (front end of compiler)
- Lexical Analysis (scanning)
- reads character stream of program and groups into meaningful sequences called lexemes.
- For each lexeme, analyser produces an output of the form
<token_name, attribute_value> token_name- used during syntax analysisattribute_value- points to an entry in the symbol table for this token.- Example,
position = initial + rate * 60- position - lexeme mapped to
'=','+','*'-><=/+/*>; no second value as there is no associated value in symbol table- initial - mapped to
- rate - mapped to
- 60 ->
<number,60> - After lexical analysis, example statement would look like
<id,1> <=> <id,2> <+> <id,3> * <number,60>
- position - lexeme mapped to
- Outputs stream of tokens for parser
- Syntax Analysis (parsing)
- Generates Syntax tree to represent grammatical structure of the token stream
- The tree shows the order in which the operations in a statement are to be performed.
- CFGs (Context Free Grammar) are used to construct the syntax trees
- Semantic Analysis
syntax tree + symbol tableto check for semantic consistency with language definition- Gathers type information, and stores it in syntax tree or symbol table.
- Performs
type checking(e.g. floating point index of an array ERR message) coercions- forceful, implicit typecasting. (int to float)
- Intermediate Code Generation
- The generated code here should be easy to produce and easy to translate into machine code
- Code Optimization
- faster, shorter, less power consuming are all examples of improved code.
- Optimising Compilers take a significant amount of time in this phase, but significantly improve the run time of the target program as well.
- Code Generation
- Intermediate representation of src program mapped to target language
- crucial part is the assignment of registers to hold variables at machine level.
Symbol Table Management
- Symbol Table[2^] should be designed to allow compiler to find the record for each name quickly and to store or retrieve data from that record quickly.
Chapter 2 - A Simple Syntax-Directed Translator¶
Syntax Definition¶
- Syntax of a programming language describes the proper form of its programs.
GRAMMAR (Context Free Grammar):
- Used to specify the syntax of a language
- Describes hierarchical structure of most programming language constructs.
if (expression) statement else statement- The above statement can be expressed as:
stmt -> if (expr) stmt else stmt- The
->may be read as "can have the form". The above rule can be called a production.
- In a production, lexical elements like keywords if, else, parentheses are called terminals*.
- Variables like expr and stmt represent sequences of terminals and are called non-terminals
- The above statement can be expressed as:
- A CFG has four components:
- Set of terminals (tokens)
- Set of non-terminals (Syntactic variables)
- Set of productions
- A non-terminal (head or left side of the production)
- An Arrow
- Sequence of terminals and/or non-terminals (body or right side of the production)
S -> aA | Aa
- Designation of one of the non-terminals as the start symbol.
- Derivations
- Grammar derives strings by beginning with start symbol and repeatedly replacing a non-terminal by body of a production for that non-terminal.
- Language defined by grammar is the terminal strings that can be derived from the start symbol.
- Parsing
- It is the problem of taking a string of terminals and figuring out how to derive it from the start symbol of the grammar
- If it cannot be derived, then reporting syntax errors within the string.
- It is one of the fundamental problems in all of compiling.
- It is the problem of taking a string of terminals and figuring out how to derive it from the start symbol of the grammar
- Parse Trees
- Pictorially shows how the start symbol of a grammar derives a string in the language. Example,
A -> XYZ
- Given a CFG, a parse tree is a tree with the following properties:
- Root Node -> Start Symbol
- Leaf Node -> Terminal | ε
- Interior Node -> Non-Terminal
- If XYZ are present with a parent node A. Then there must exist a production A such that A->XYZ.
- Pictorially shows how the start symbol of a grammar derives a string in the language. Example,
- Ambiguity
- When a grammar can generate more than one parse tree for a given string of terminals. It is ambiguous.
- String with more than one parse tree usually has more than one meaning.
- We need to either design unambiguous grammars for compiling applications or use ambiguous grammars with additional rules to resolve the ambiguities.
- Associativity of Operators
- When an operand has operators to its left and right, conventions are required for deciding which operator applies to that operand.
(+|-|*|/)are left associative i.e. \(5*4*6\ =\ (5*4)*6\)(=|^)are right associative i.e. \(a=b=c\) -> \(a=(b=c)\) anda^b^cis treated asa^(b^c)- Right associative operator grammar example:
right -> letter = right | letter
letter -> a | b | ... | z
- Right associative operator grammar example:
- Operator Precedence
- Rules are needed when more than one kind of operator is present.
- Example, let's say we want to work with operators +,-,*,/
- We have two levels of precedence: (*, /) and (+,-)
- We start by creating 2 non-terminals expr and term for the two levels of precedence AND and extra non-terminal factor for generating basic units in expressions.
- Start with the lowest precedence, to match the highest precedence terminals first.
- Note that, the lowest nodes in the tree are evaluated first, that's why start with lower precedence.
\(term\ -> term\ *\ factor\ |\ term\ /\ factor\ |\ factor\) - GRAMMAR
- \(factor\ -> digit \ |\ (expr)\)
- \(expr\ ->\ expr+term\ |\ expr-term\ |\ term\)
- \(term\ -> term\ *\ factor\ |\ term\ /\ factor\ |\ factor\)
- Here, we separated the productions based on the precedence level.
- We put the same level of precedence on the same production and added a Non-terminal factor which would be giving us the terminal digit.
- factor[3^] in the above grammar is an expression which cannot be "torn apart"[4^] by any operator. It would either be a digit or would act within itself as it is closed within parentheses.
- Generalising the Idea
- We can generalise this idea of precedence of operators to
nprecedence levels. We just needn+1non-terminals. - first, like factor production above, can never be torn apart is the base case.
- The production bodies for this non-terminal are only single operands and parenthesised expressions
- Then, for each precedence level, there is one non-terminal representing expressions that can be torn apart only by operators at that level or higher.
- The productions for this non-terminal would have bodies representing uses of the operators at that level, plus one body that is just the non-terminal for the next higher level.
- Example - lowest level would have assignment and comparison operators and a non-terminal for additionSubtraction non-terminal, etc.
- We can generalise this idea of precedence of operators to
- Syntax Directed Translation
- Attributes
- Any quantity associated with a programming construct
- E.g. Data types of expressions, number of instructions in generated code, location of the first instruction in the generated code.
- (Syntax-directed) Translation Schemes
- Notation for attaching program fragments to the productions of a grammar.
- Program fragments are executed when the production is used during syntax analysis.
- Attributes
- Postfix Notation
- Postfix notation for an expression E is defined as follows:
- E is a variable/constant -> Postfix is E itself
- E is an expressions of form
E1 op E2-> Postfix is \(E_1^{'}E_2^{'}op\) where \(E_1^{'}\) and \(E_2^{'}\) are the postfix notations for E1 and E2 respectively. - E is a parenthesised expression of the form (E1), then the postfix notation for E is the same as the postfix notation for E1.
- Since, parenthesis avoids the term form tearing apart!
- No parenthesis needed. position and arity(number of args) of operators permits only one way of decoding the postfix notation.
- Postfix notation for an expression E is defined as follows:
- Synthesised Attributes
- Attribute is said to be synthesised if its value at a parse-tree node N is determined from attribute values at the children of N and at N itself.
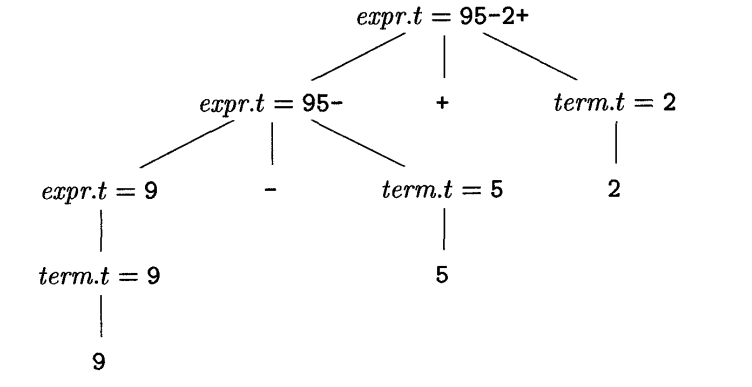
Parsing:¶
- Recursive Descent
- Parsing Method Classes:
- The order in which nodes in the parse tree are constructed.
- Top-down OR Bottom Up
- Top Down parsers:
- construction starts at the root, proceeds towards leaves
- An efficient parser can more easily be constructed by hand with this method.
- Bottom up parser:
- Can handle a large class of grammars and translation schemes.
- Often used by software tools.
- Top Down Parsing:
- STEPS
- Start at the root,and perform following two steps in repeat:
- At Node N, labelled with Non-Terminal A. Select one of the productions for A and construct children at N for the symbols in the production body.
- Find the next node at which a sub-tree is to be constructed, typically the leftmost not expanded non-terminal of the tree
- Layman Terms
- Take a root Node N.
- Select one of the productions having a prefix match with the current lookahead (cursor) symbol.
- since they match, move cursor ahead and find next node at which subtree is to be constructed. (Go down more levels for the new non-terminals found on this level -- Ideally from left-to-right)
- STEPS
- Predictive Parsing - (A simple form of recursive descent)
- Relies on information about the first symbols that can be generated by a production body.
- FIRST(\(\alpha\)) - set of terminals that appear as the first symbols of one or more strings of terminals generated from \(\alpha\).
- The FIRST sets must be considered if there are two productions:
- \(A\ ->\ \alpha\)
- \(A\ ->\ \beta\).
- The lookahead symbol is then used to decide which production to use.
- Predictive parsing required FIRST(\(\alpha\)) and FIRST(\(\beta\)) to be disjoint. Why? So that the lookahead symbol can be directly used to decide which production to use without any conflicts.
- Relies on information about the first symbols that can be generated by a production body.
LEFT Recursion¶
- A Recursive-descent parser might loop forever.
- \(expr\ \rightarrow\ expr\ +\ term\)
- Where the leftmost symbol is the same as the nonterminal at the head of the production.
- left-recursive production can be eliminated by rewriting the offending production.
- \(A\ \rightarrow\ A\alpha\ | \ \beta\) i.e \(expr\ \rightarrow\ expr\ +\ term \ |\ term\)
- How can all left recursion be eliminated from the grammar? Syntax Analysis#
LEFT RECURSION REMOVAL¶
- \(A\rightarrow \ A\alpha \ | \ \beta\) \(\leftarrow\) Compare the productions with this form
- Convert the above components to following:
- \(A \rightarrow \beta A^{'}\) and \(A^{'}\rightarrow\alpha A\ | \ \epsilon\)
- Example, \(expr\ \rightarrow\ expr\ +\ term \ |\ term\)
- Here, A = expr, \(\alpha\) = + term, \(\beta\) = term
- \(expr \rightarrow term\ expr^{'}\)
- \(expr^{'} \rightarrow +\ term\ expr^{'} \ | \ \epsilon\)
-
Recursive Descent Parsers cannot be implemented with LEFT-RECURSION.
- Why? It would end up looping forever
- If there is left recursion, convert it to right recursion.
-
Abstract Syntax Trees (Syntax trees) -> interior nodes represent an operator, children represent operands for the operator
- Parse Trees (aka concrete syntax tree) -> Interior Nodes represent Non-terminals, leaf nodes represent the terminals. | underlying grammar called concrete grammar.
Lexical Analysis¶
- lexical analyzer reads characters from the input and groups them into "token objects."
- Refer \(\rightarrow\)Lexical Analysis
Symbol Table¶
- Data Structures used by compilers; holds information about source-program constructs.
- Lexical Analyzer creates these entries during the analysis phase in the form
<token_name, attribute_value> - SYMBOL TABLE PER SCOPE
- Same identifier can be declared in different parts of a program
Summary & IMPs¶
- Predictive parser cannot handle a left-recursive grammar. #LEFT RECURSION REMOVAL
Foot Notes¶
[1^]: Syntax and Semantics - Syntax is structure of language(statements, expressions, program units). Semantics is meaning of individual tokens of language.
[2^]: Symbol Table - Information related to identifier, constant, function, method is stored. A data structure that has record for each variable name with fields for the attributes of the name.
[3^]: Factor - An expression that cannot be "torn apart" by any operator. That is, placing an operator next to any factor, on either side, does not change the way the factor would be working/calculated as an individual entity. If the factor is a parenthesis entity; parenthesis protect it against such tearing while if the factor is a single operand such as a digit. It cannot be torn apart.
[4^]: Tear apart - A term (that is not a factor [3^] ) is an expression that can be torn apart by operators of higher precedence but not by the lower-precedence operators. An expression of the lowest precedence can be torn apart by any operator.